Integrated Alerting in Dagster+
Designing alerts that are actionable, contextual, and trustworthy
Overview
Alerting is one of the most trust-sensitive capabilities in a data platform. When alerts lack context or interrupt users at the wrong time, they quickly become noise. When they fail, the cost is missed incidents and lost confidence.
This work focused on redesigning alerting in Dagster+ as a cohesive product system — spanning policy creation, state modeling, in-product visibility, and external delivery through Slack and email.
The Problem
The issue wasn't whether alerts fired. It was whether they represented something users actually cared about.
As adoption grew, alerting behavior became fragmented:
- •Policies were configured in isolation
- •Alerts were triggered on individual signals rather than meaningful state changes
- •Notifications lacked sufficient context to act
- •Slack and email delivery were disconnected from product surfaces
- •Alert fatigue reduced trust in the system
Design Objective
Design an alerting system that:
- •Treats alerts as part of everyday workflows
- •Preserves context from configuration through action
- •Reduces noise without hiding real issues
- •Maintains consistency across product, Slack, and email
Alerting needed to function as system behavior — not a standalone page.
Design Solution
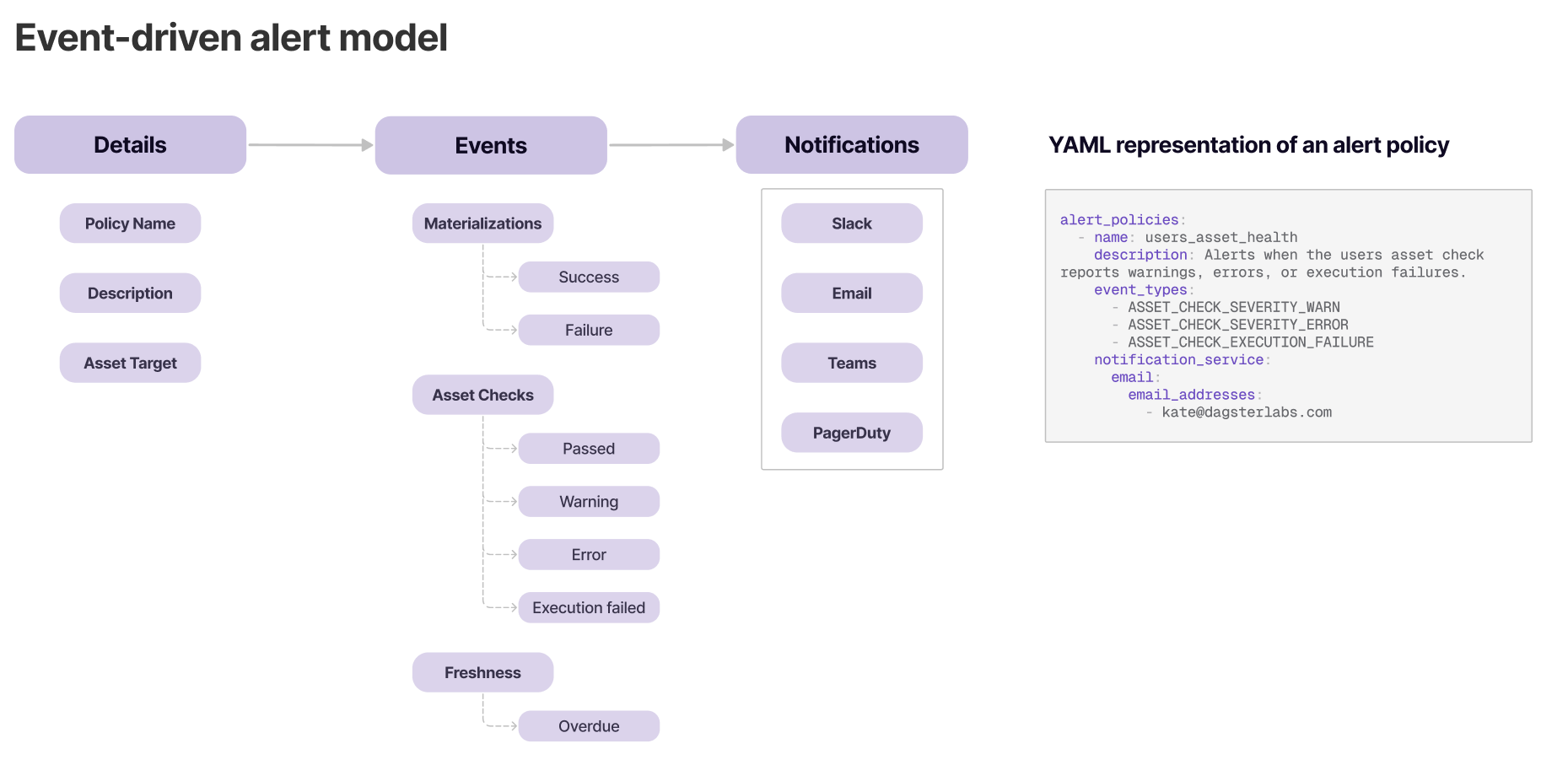
Alert Policies as First-Class Concepts
Alert policies were designed to clearly communicate:
- •What is being monitored
- •When alerts fire
- •Where notifications are delivered
- •Who owns response
Configuration needed to feel predictable and transparent — especially in high-stakes production environments. As targeting needs grew more complex, we expanded alert policies from selecting assets by name to supporting dynamic targeting through selection syntax and saved views. This allowed teams to define alert scope based on logical groupings and system behavior rather than static identifiers. The goal was flexibility without sacrificing predictability.
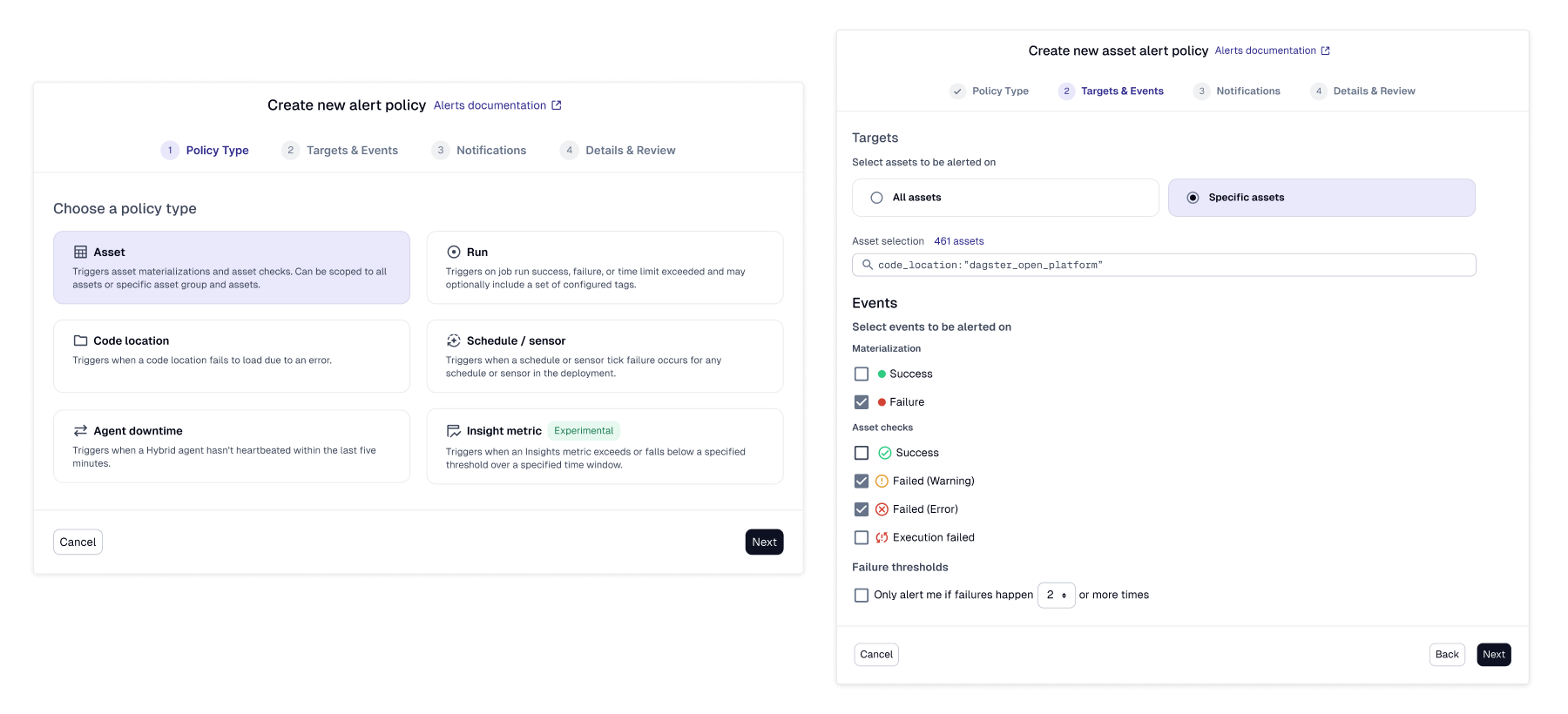
Alerts Embedded in Product Context
Alerts were surfaced directly within relevant product surfaces — such as asset and run views — rather than being confined to a dedicated alerts page.
This reduced context switching and allowed users to:
- •See current health state
- •Review recent events
- •Understand impact
- •Act immediately
Alerting became part of the operational workflow, not an interruption outside it.
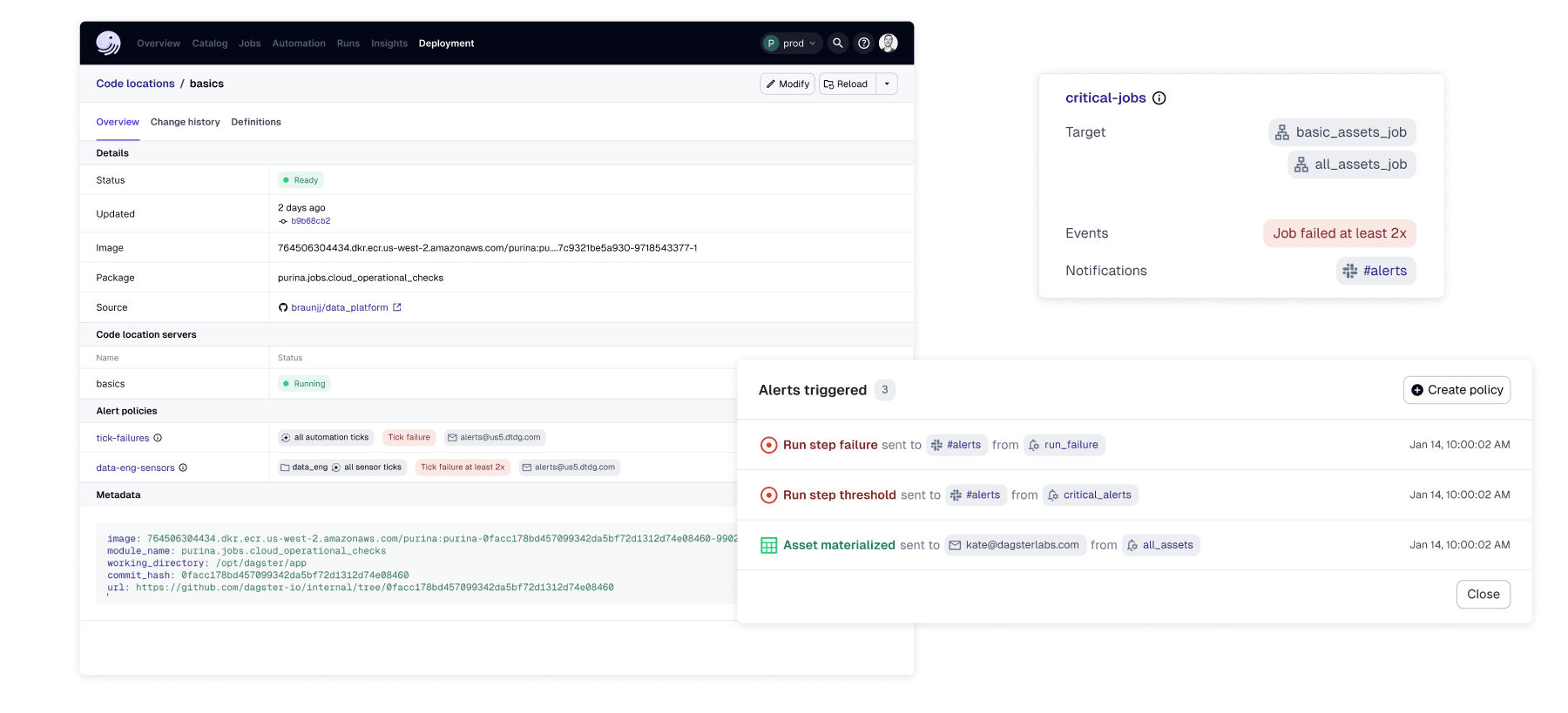
From Events to Health Status
As we expanded alerting across product and external channels, we noticed a recurring issue: even well-configured alerts were firing too frequently.
Teams were being notified about individual events — retries, partial failures, transient warnings — that didn't always reflect meaningful system degradation.
The system was working as designed, but the model of "alert on every signal" was flawed.
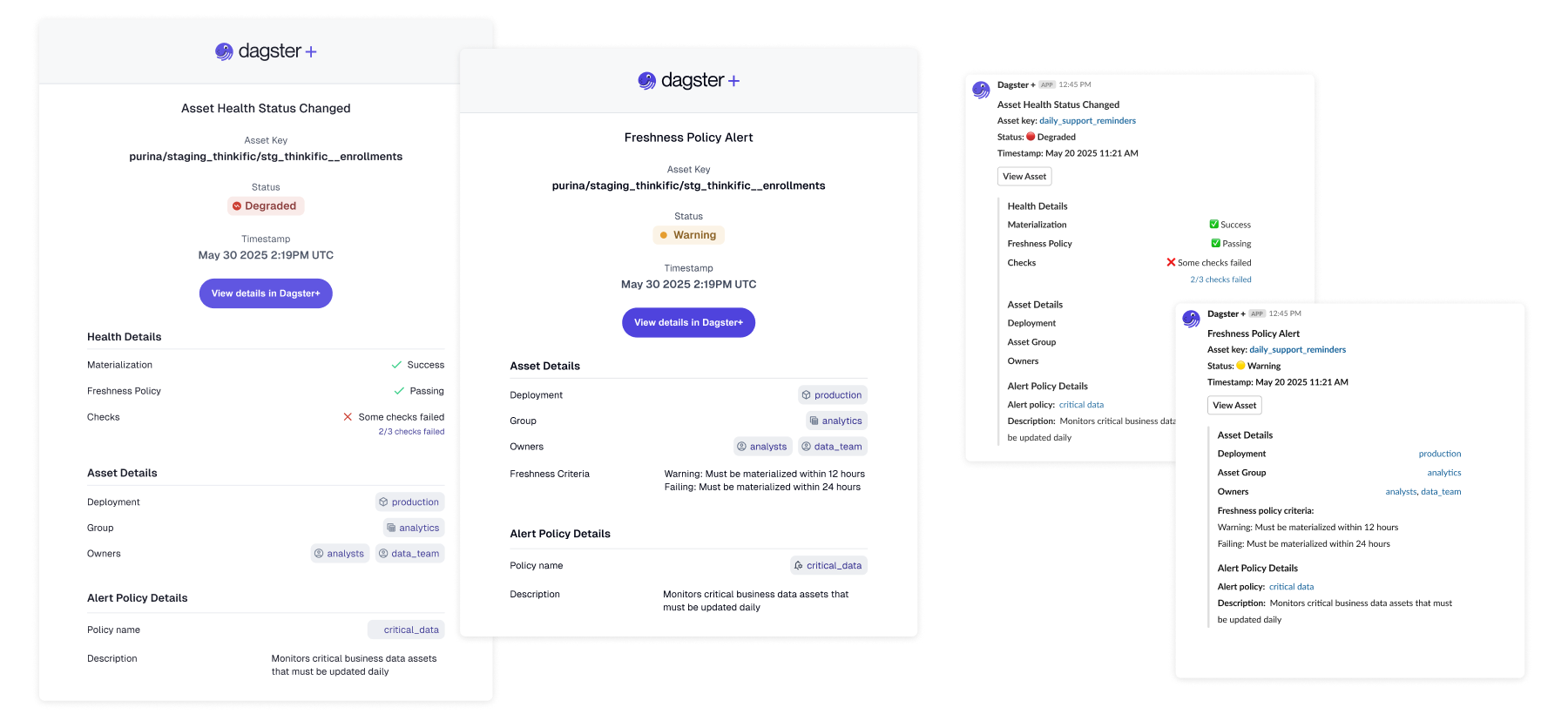
We introduced asset health status as a consolidated state model that aggregates signals into meaningful transitions. Alerts could now fire on state changes — Healthy → Degraded → Failed — rather than on isolated events.
This reduced noise while increasing confidence in what alerts represent. This shifted the underlying model from event-based alerting to state-based alerting — a fundamental change in how the system communicated with users.
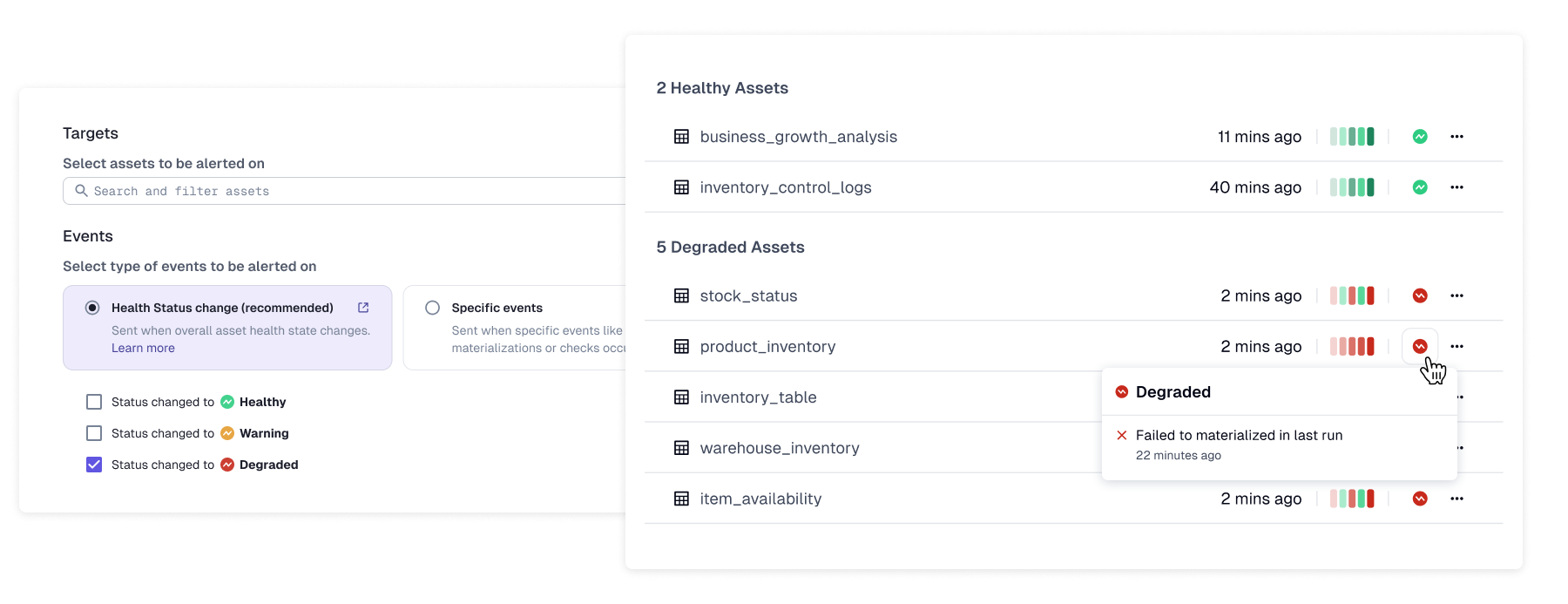
Cross-Surface Delivery: Slack and Email
Slack and email notifications carried forward the same health-based model used in the product UI.
Each notification included:
- •Current health state
- •Relevant event context
- •Clear ownership
- •Deep links back into Dagster+
By aligning delivery channels with the same underlying system model, we ensured consistency across surfaces.
Users no longer had to reconstruct state from fragments — the system spoke the same language everywhere.
Design Tradeoffs
Noise vs. Coverage
Alerting on every signal increases coverage but erodes trust. We prioritized meaningful state changes over exhaustive event reporting.
Flexibility vs. Predictability
Customization remained possible, but policy behavior had to stay understandable at a glance.
Visibility vs. Interruption
Alerts were surfaced where they clarified operational context — not where they distracted from it.
Outcome
By consolidating signals into health status and aligning policy configuration with consistent cross-surface delivery, alerting in Dagster+ became:
- •Easier to configure
- •Easier to interpret
- •Easier to act on
- •More trustworthy over time
Rather than adding more alerts, we focused on making alerts represent something meaningful.
Key Takeaways
- •Alerting is fundamentally about human attention
- •State changes are more actionable than raw events
- •Consistency across surfaces builds long-term trust
- •Systems thinking reduces noise without sacrificing awareness